Facebook Reality Labs, the company’s R&D division, has been leading the charge on making virtual reality avatars realistic enough to cross the dreaded ‘uncanney valley’. New research from the group aims to support novel facial expressions so that your friends will accurately see your silly faces VR.
Most avatars used in virtual reality today are more cartoon than human, largely as a way to avoid the ‘uncanny valley’ problem—where more ‘realistic’ avatars become increasingly visually off-putting as they get near, but not near enough, to how a human actually looks and moves.
The Predecessor: Codec Avatars
The ‘Codec Avatar’ project at Facebook Reality Labs aims to cross the uncanny valley by using a combination of machine learning and computer vision to create hyper-realistic representations of users. By training the system to understand what a person’s face looks like and then tasking it with recreating that look based on inputs from cameras inside of a VR headset, the project has demonstrated some truly impressive results.
Recreating typical facial poses with enough accuracy to be convincing is already a challenge, but then there’s a myriad of edge-cases to deal with, any of which can throw the whole system off and dive the avatar right back into the uncanny valley.
The big challenge, Facebook researchers say, is that it’s “impractical to have a uniform sample of all possible [facial] expressions” because there’s simply so many different ways that one can contort their face. Ultimately this means there’s a gap in the system’s example data, leaving it confused when it sees something new.
The Successor: Modular Codec Avatars
{kind=link}
Researchers Hang Chu, Shugao Ma, Fernando De la Torre, Sanja Fidler, and Yaser Sheikh from the University of Toronto, Vector Institute, and Facebook Reality Labs, propose a solution in a newly published research paper titled Expressive Telepresence via Modular Codec Avatars.
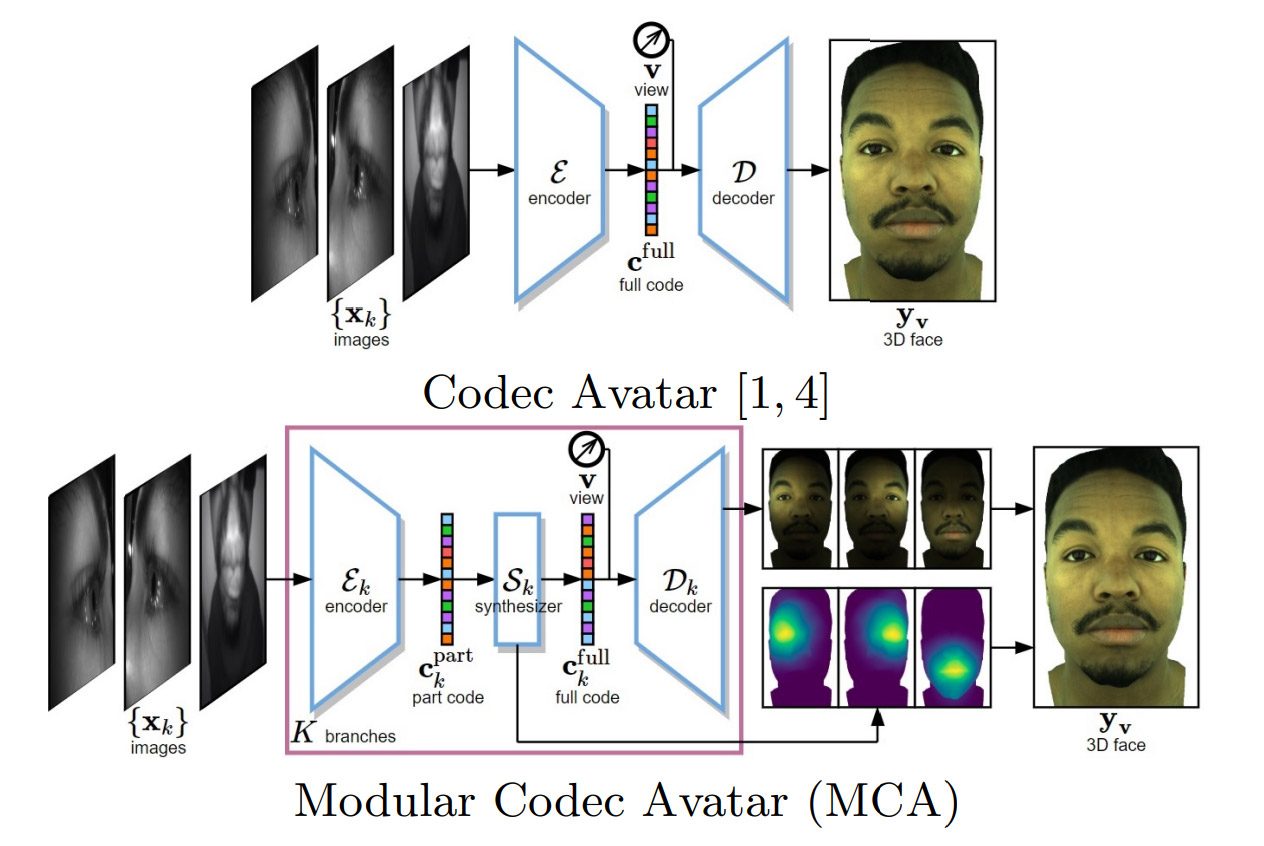
While the original Codec Avatar system looks to match an entire facial expression from its dataset to the input that it sees, the Modular Codec Avatar system divides the task by individual facial features—like each eye and the mouth—allowing it to synthesize the most accurate pose by fusing the best match from several different poses in its knowledge.
In Modular Codec Avatars, a modular encoder first extracts information inside each single headset-mounted camera view. This is followed by a modular synthesizer that estimates a full face expression along with its blending weights from the information extracted within the same modular branch. Finally, multiple estimated 3D faces are aggregated from different modules and blended together to form the final face output.
The goal is to improve the range of expressions that can be accurately represented without needing to feed the system more training data. You could say that the Modular Codec Avatar system is designed to be better at making inferences about what a face should look like compared to the original Codec Avatar system which relied more on direct comparison.
The Challenge of Representing Goofy Faces
One of the major benefits of this approach is improving the system’s ability to recreate novel facial expressions which it wasn’t trained against in the first place—like when people intentionally contort their faces in ways which are funny specifically because people don’t normally make such faces. The researchers called out this particular benefit in their paper, saying that “making funny expressions is part of social interaction. The Modular Codec Avatar model can naturally better facilitate this task due to stronger expressiveness.”
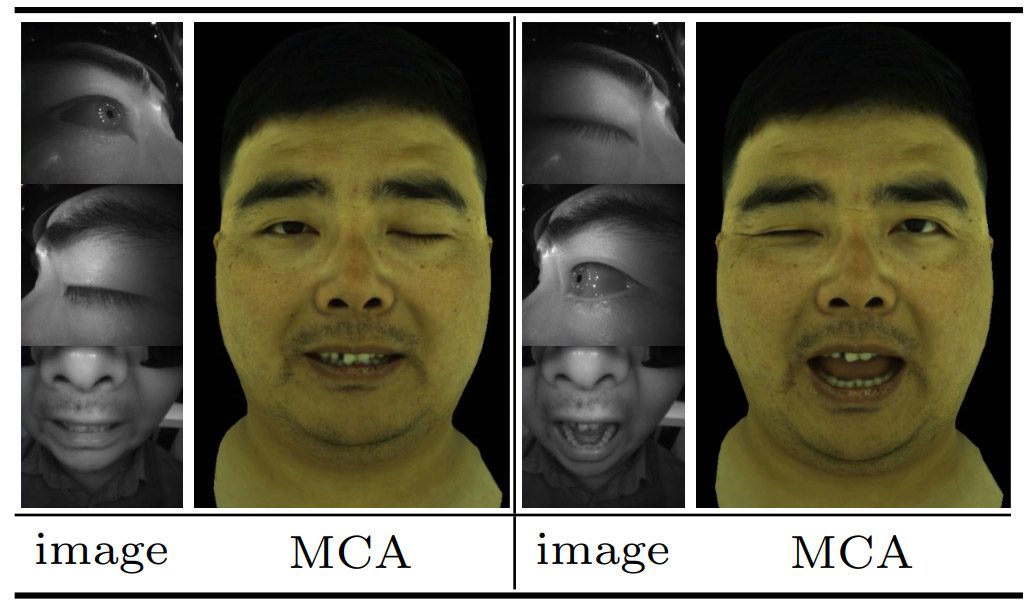
They tested this by making ‘artificial’ funny faces by randomly shuffling face features from completely different poses (ie: left eye from {pose A}, right eye from {pose B}, and mouth from {pose C}) and looked to see if the system could produce realistic results given the unexpectedly dissimilar feature input.
{kind=link}
“It can be seen [in the figure above] that Modular Codec Avatars produce natural flexible expressions, even though such expressions have never been seen holistically in the training set,” the researchers say.
As the ultimate challenge for this aspect of the system, I’d love to see its attempt at recreating the incredible facial contortions of Jim Carrey.
Eye Amplification
Beyond making funny faces, the researchers found that the Modular Codec Avatar system can also improve facial realism by negating the difference in eye-pose that is inherent with wearing a headset.
In practical VR telepresence, we observe users often do not open their eyes to the full natural extend. This maybe due to muscle pressure from the headset wearing, and display light sources near the eyes. We introduce an eye amplification control knob to address this issue.
This allows the system to subtly modify the eyes to be closer to how they would actually look if the user wasn’t wearing a headset.
{kind=link}
– – – – –
While the idea of recreating faces by fusing together features from disparate pieces of example data isn’t itself entirely new, the researchers say that “instead of using linear or shallow features on the 3D mesh [like prior methods], our modules take place in latent spaces learned by deep neural networks. This enables capturing of complex non-linear effects, and producing facial animation with a new level of realism.”
The approach is also an effort to make this kind of avatar representation a bit more practical. The training data necessary to achieve good results with Codec Avatars requires first capturing the real user’s face across many complex facial poses. Modular Codec Avatars achieve similar results with greater expressiveness on less training data.
It’ll still be a while before anyone without access to a face-scanning lightstage will be able to be represented so accurately in VR, but with continued progress it seems plausible that one day users could capture their own face model quickly and easily through a smartphone app and then upload it as the basis for an avatar which crosses the uncanny valley.